Funkcjonalność - Global Endpoint Deduplication™
 Deduplikacja to technologia kompresji danych umożliwiająca eliminację zduplikowanych kopii powtarzających się danych. W procesie deduplikacji unikalne porcje danych są identyfikowane i zapisywane w przestrzeni składowania danych. Następne porcje danych są analizowane i porównywane z już przechowywanymi i jak tylko algorytmy wykryją powtórzenie to zapisywane są wyłącznie referencje do unikalnych danych.
Deduplikacja to technologia kompresji danych umożliwiająca eliminację zduplikowanych kopii powtarzających się danych. W procesie deduplikacji unikalne porcje danych są identyfikowane i zapisywane w przestrzeni składowania danych. Następne porcje danych są analizowane i porównywane z już przechowywanymi i jak tylko algorytmy wykryją powtórzenie to zapisywane są wyłącznie referencje do unikalnych danych.
Global Endpoint Deduplication™ - to technologia implementująca deduplikację blokową ze zmiennym blokiem danych dostępną zarówno po stronie źródła danych (na kliencie - Source) jak i miejsca składowania danych (serwer backupowy - Target). Jest to także deduplikacja globalna umożliwiająca wykonywanie deduplikacji na dowolnym kliencie i dowolnym zadaniu backupowym podłączonym do serwera backupowego.
Funkcjonalność ta została stworzona przez inżynierów firmy Inteos Sp. z o.o. i zaadoptowana w Bacula Enterprise Edition 8 przez Bacula Systems.
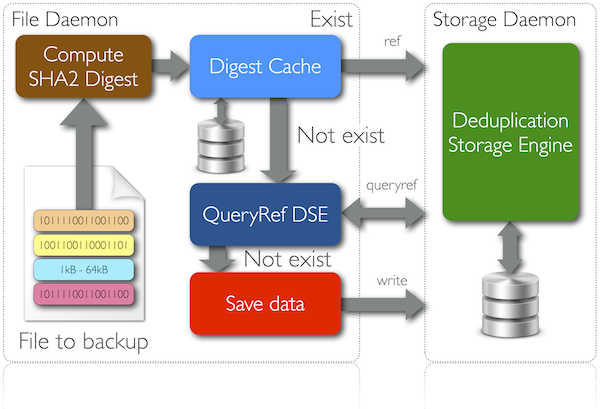
Podczas backupu plik dzielony jest na bloki o określonej wielkości. Następnie dla każdego bloku wyliczana jest suma kontrolna (kryptograficzna funkcja skrótu - SHA256). Suma ta weryfikowana jest w lokalnej bazie cache i jeśli zostanie tam znaleziona to do serwera backupowego przesyłana jest wyłącznie informacja referencyjna. Jeśli suma nie zostanie znaleziona w bazie cache to wysyłane jest zapytanie do serwera backupowego i w zależności od otrzymanej odpowiedzi do serwera backupowego wysyłany jest cały blok danych lub tylko referencja.
Schemat zasady działania deduplikacji po stronie klienta podczas zadań backupowych (Deduplication on Source) przedstawia poniższy rysunek:
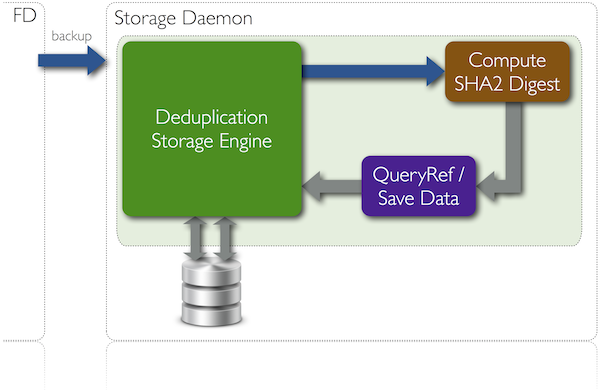
Deduplikacja po stronie serwera backupowego jest znacznie prostsza choć algorytm działania jest analogiczny do poprzedniego. Dla bloków otrzymanych od klienta jest wyliczana suma kontrolna (SHA256) i w zależności od tego czy dany blok był już wcześniej zapisany czy nie następuje zapis referencji lub całego bloku. Zapytanie trafia do tego samego silnika deduplikacyjnego co w przypadku deduplikacji na kliencie i wszystkie zadania korzystają z tej samej bazy deduplikatów.
Schemat działania deduplikacji w przypadku wykonywania jej po stronie serwera backupowego:
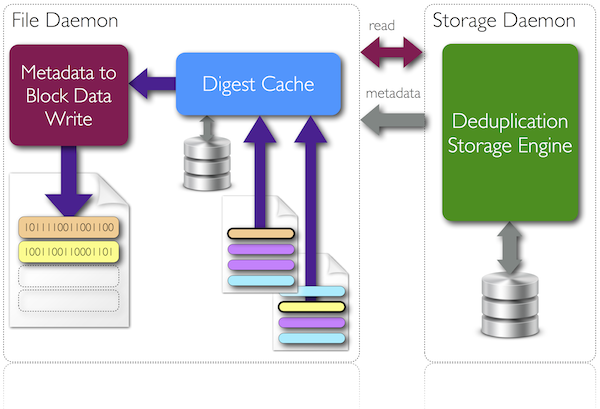
Podczas odtwarzania w pierwszej kolejności wysyłane są metadane deduplikacyjne na podstawie których klient poszukuje lokalnych bloków wymaganych do odtworzenia. Jeśli je znajdzie to są one używane, w przeciwnym razie odpowiedni blok jest pobierany z serwera backupowego. W zależności od okoliczności może okazac się że fizycznie odtwarzane dane z serwera backupowego to tylko 10% całości odtwarzanych danych.
Schemat działania częściowego odtwarzania:
Podsumowanie funkcjonalności Global Endpoint Deduplication™:
- deduplikacja blokowa
- wykonywana na kliencie (Source)
- wykonywana na serwerze (Target)
- deduplikacja globalna
- przesyła tylko nieistniejące na serwerze backupowym bloki
- dla dowolnego klienta
- dla dowolnego zadania
- częściowe odtwarzanie (partial restore) na dowolnym kliencie i dowolnym pliku (także odtwarzanie na innego wskazanego klienta)
- wspólna baza deduplikatów dla wszystkich zadań i klientów
Jeśli chciałbyś się dowiedzieć więcej na temat tej funkcjonalności, to skontaktuj się z nami.


 Copyright © 2010 by
Copyright © 2010 by